
Chinese Text Simplification for Reading Comprehension (Part 4)
Part 4 Summary
In this section, I will discuss the performance of my custom lexical simplification pipeline, fine-tuned BART pipeline, and combination approaches. I also cover the NLP metrics used to evaluate the performance on the MCTS dataset.
Evaluating the performance of my models
Having spent the last two parts of this project (1) building a LS pipeline and (2) fine-tuning BART for a TS pipeline, let's evaluate the performance of these methods.
Performance metrics
I will be scoring the model performance using four metrics: SARI, BERTscoreprecision, L1-3 % change, and the frequency rank2 % change. Let's discuss in detail:
- SARI: System output Against References and Input. A measure of the words added, kept, or deleted from the original sentence and compared with an ideal reference [1].
- BERTscoreprecision: a scoring metric using BERT embedding to calculate cosine similarity between outputs and references [2]. I will take the precision value output of the BERTscore.
- L1-3 % change: similar to the metric used in the MCST paper [3], I will measure the proportion of words in the original and output sentences that are in the HSK 1-3 range. I calculate the percent increase of this proportion to see if the output sentence contains generally simpler words.
- Frequency rank2 % change: like L1-3 % change, I calculate the percent change of the mean squared frequency rank of from the original to output sentences. A reminder that the frequency rank is based on BLCU data, with rank=1 meaning it is the top most frequent appearing word in the BLCU dataset. Since the distribution lies between 0 and 1 with a high skew towards 1, I square the rank values to provide greater separation. Like L1-3 % change, this metric measures if the output sentence contains words which are higher on the frequency ranking, i.e. that are more commonly used. More commonly used words are more likely to be known to any given reader, and more likely to be simple.
Models/pipelines to evaluate
So far, we have discuss a lexical simplification approach using a custom pipeline, and a text simplification approach using a BART model. In addition, I want to evaluate two more models: the first is applying the LS pipeline before sending the input to BART, and the second is applying the LS pipeline after getting the output from BART. I will respectively refer to these models as LS-BART and BART-LS, describing the order of the operations.
Let's set up the various model pipelines. Here, the LS_pipeline() function is the lexical simplification pipeline I described in detail in Part 2 of this project, with all required packages, while fine_tuned_BART is the model I tuned in Part 3.
from transformers import BertTokenizer, BartForConditionalGeneration, Text2TextGenerationPipeline
tokenizer = BertTokenizer.from_pretrained("fine_tuned_BART", local_files_only=True)
model = BartForConditionalGeneration.from_pretrained("fine_tuned_BART", local_files_only=True)
text2text_generator = Text2TextGenerationPipeline(model, tokenizer)
def LS_pipeline(sentence: str):
###Code from Part 2 goes here###
return LS_simplified_sentence: str
def TS_with_BART(sentence: str):
simple_sentence = text2text_generator(sentence, max_length=128, do_sample=False)[0]['generated_text'].replace(" ","")
return simple_sentence
def TS_with_LS_BART(sentence: str):
ls_sentence = LS_pipeline(sentence)
simple_sentence = TS_with_BART(ls_sentence)
return simple_sentence
def TS_with_BART_LS(sentence: str):
bart_sentence = TS_with_BART(sentence)
simple_sentence = LS_pipeline(bart_sentence)
return simple_sentence
Preparing the datasets and metric computations
Now that the models are ready to go, let's prep the evaluation data and the four metrics discussed earlier. As a reminder, I'm using the human-created text simplification dataset from the MCTS paper [3], which contains a validation set of 366 sentences, with five reference simplifications per sentence. The metrics will be computed as the average values across all sentences.
#imports:
import pandas as pd
import numpy as np
import jieba
import pickle
from evaluate import load
# scoring metrics:
sari = load("sari")
bertscore = load("bertscore")
# vocab frequency and HSK data:
blcu = pd.read_csv('BLCU/literature_wordfreq.release_UTF-8.txt', header = None, sep="\t",)
blcu.rename(columns={0:"character", 1:"frequency"}, inplace=True)
blcu.set_index("character", inplace=True)
blcu["frequency"] = blcu["frequency"].rank(pct=True)
blcu = blcu.to_dict()['frequency']
with open("HSK_levels.pickle", 'rb') as handle: # this is HSK level data from Part 2, saved to Pickle!
hsk_dict = pickle.load(handle)
# parallel sentence data:
with open('mcts/mcts.dev.orig', encoding="utf8") as f:
mcts_orig = f.readlines()
mcts_ref = []
for dataset in range(0,5):
filename = str('mcts/mcts.dev.simp.'+str(dataset))
with open(filename, encoding="utf8") as f:
mcts_ref.append(f.readlines())
With the datasets loaded, let's create some functions to calculate L1-3 and rank2 as well as some required preprocessing:
def chinese_tokenizer(data: list):
return [" ".join(jieba.cut(sentence)) for sentence in data] # tokenizes Chinese words with spaces
def sentence_metrics(sentence):
tokens = [word for word in jieba.cut(sentence)] # get tokens
## find portion of words in HSK level 1-3:
levels = [hsk_dict[word] for word in tokens if word in hsk_dict]
if levels:
l13 = (levels.count(1) + levels.count(2) + levels.count(3))/len(tokens)
else:
l13 = 0
## find frequency of words:
freqs = [np.power(blcu[word], 2) for word in tokens if word in blcu] # get squared frequency
freq = np.mean(freqs) # mean of squared freqs
return l13, freq
def corpus_metrics(complex_sentences: list, simple_sentences: list):
simple_metrics = [sentence_metrics(sentence) for sentence in simple_sentences]
complex_metrics = [sentence_metrics(sentence) for sentence in complex_sentences]
l13_simple = np.mean([simple_metrics[idx][0] for idx in range(len(simple_metrics))])
l13_complex = np.mean([complex_metrics[idx][0] for idx in range(len(complex_metrics))])
freq_simple = np.mean([simple_metrics[idx][1] for idx in range(len(simple_metrics))])
freq_complex = np.mean([complex_metrics[idx][1] for idx in range(len(complex_metrics))])
l13_score = 100*(l13_simple - l13_complex)/l13_complex # percent change in L1-3 proportion
freq_score = 100*(freq_simple - freq_complex)/freq_complex # percent change in squared frequency
return l13_score, freq_score
And the final wrapper function which include all four metrics:
def get_metrics_MCTS(simple_sentences: list):
return get_metrics(simple_sentences, mcts_orig, mcts_ref)
def get_metrics(simple_sentences: list, complex_sentences: list, reference_sentences: list,):
# tokenize sentences:
tokenized_simplified = chinese_tokenizer(simple_sentences)
tokenized_complex = chinese_tokenizer(complex_sentences)
tokenized_reference = [chinese_tokenizer([reference_sentences[idx][ref]
for idx in range(len(reference_sentences))])
for ref in range(len(complex_sentences))]
# Compute SARI score:
sari_score = sari.compute(
predictions=tokenized_simplified, # model output
references=tokenized_reference, # reference simple sentences
sources=tokenized_complex # complex sentence
)["sari"]
# Compute BERT precision score:
bert_score = bertscore.compute(
predictions=tokenized_simplified,
references=tokenized_reference,
lang="zh"
)["precision"][0]
# Compute L1-3 and frequency scores:
l13_score, freq_score = corpus_metrics(tokenized_complex, tokenized_simplified)
return {'sari_score': sari_score,
'bert_score': bert_score,
'l13_score': l13_score,
'freq_score': freq_score}
Running the models and evaluating!
Moment of truth, it's time to run the models on our validation data and check the output metrics:
The execution of the above code could take a while if you are only using CPU.
Here are the results on the validation set for the four models:
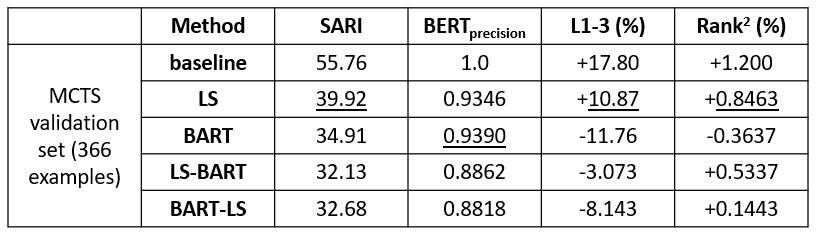
Discussion
The results indicate that our custom LS pipeline performs the best across three of our four metrics. I was surprised to see that this method surpassed the BART model even on the SARI score, whereas other literature including the MCST paper has shown better results using BART (a SARI score of 38.49)[3]. From the L1-3 and rank2 % change, it looks like the BART model is focused more on paraphrasing or rewording a sentence rather than focusing specifically on reducing the vocabulary complexity. In fact, when LS is incorporated with BART, as in LS-BART, we can see that the L1-3 and rank2 scores increase. Still, BART has a slightly higher BERTscoreprecision than the LS pipeline.
One thing not yet discussed are the runtimes of each method. In fact, the LS method is much slower than BART, because it requires the generation of several sentence embeddings for each candidate word, which currently scales poorly. If a given sentence has 5 complex words identified, and 10 potential candidate replacements for each word, then the model must embed and evaluate 5*10=50 distinct sentences. As a result, the LS method can be tens-of-times slower than the BART evaluation.
The results so far indicate that there is plenty of further work to be done if I want to improve the models further. On one hand, I can try to further optimize the LS pipeline to increase its computation speed as well as its metric scores. On the other hand, I can try performing a hyperparameter search for the BART fine-tuning, in order to better train it on our data. Since it appears that the pseudo data used for fine-tuning does not contain enough word simplification on the reference side, I could also try applying the LS method on the pseudo references and use the new simplified data to fine tune BART, hopefully achieving both higher metrics while maintaining evaluation speed.
References
[1] Xu et al., "Optimizing Statistical Machine Translation for Text Simplification," Trans. Comp. Ling. 4, pp. 401-415, https://www.aclweb.org/anthology/Q16-1029 (2016)
[2] Zhang & Kishore et al., "BERTScore: Evaluating Text Generation with BERT," Proc. Int. Conf. Learning Representations, https://openreview.net/forum?id=SkeHuCVFDr (2020)
[3] Chong et al., "MCTS: A Multi-Reference Chinese Text Simplification Dataset," https://doi.org/10.48550/arXiv.2306.02796 (2024)