
Chinese Text Simplification for Reading Comprehension (Part 2)
Part 2 Summary
I dive into a Lexical Simplification pipeline using NLP: tokenization, NER, complex word identification, finding suitable substitution candidates, and replacing words iteratively in the text.
Applying NLP LS approaches to Chinese text
To recap my problem, I want to implement a lexical simplification (LS) pipeline for simplifying Chinese sentences. While NLP has been revolutionized by the use of large language models (LLMs) like GPT, previous NLP techniques could still be useful as they could be less computationally intensive and do not require long training times with large amounts of data. Because the approach is rather simplified, I only aim for lexical Simplification (word replacement) rather than a complex sentence simplification with grammatical and structural changes. I will save the complete text simplification method for my BART model in Part 3.
I will implement a custom LS approach shown in the diagram below. To summarize, we (1) perform named entity recognition (NER), (2) find complex words in the sentence, (3) find candidate words for substitution, (4) determine the best fit among the candidates, and (5) replace the word in the sentence. This occurs iteratively, so a sentence with multiple complex words will be simplified word-by-word. I include the additional step of NER so that named entities are not accidentally simplified, which would alter or destroy significant meaning of the sentence.
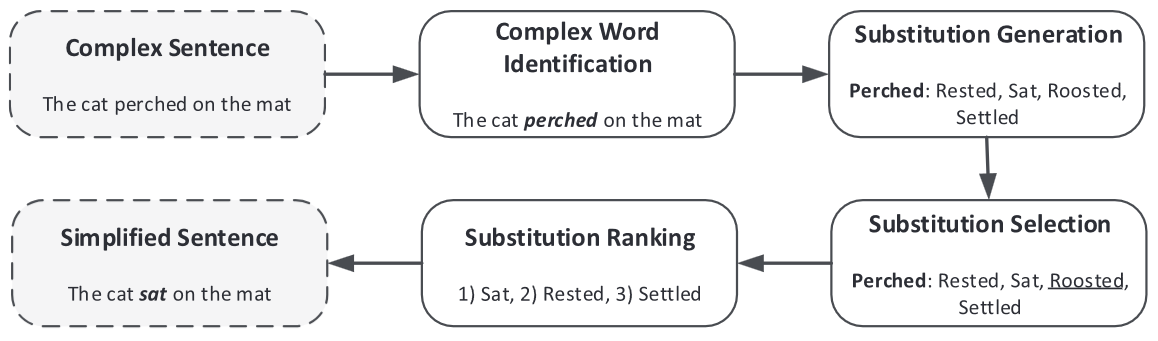
Some context on Chinese language: the individual words of a sentence are comprised of characters, of which there are many thousands. Words are typically one, two, or three characters long. Expressions can be three or four characters long (e.g. similar to English terms like "social media", a single concept described across two words). A benefit of implementing LS in Chinese is that individual Chinese characters and words are immutable. The characters of a word do not change based on subject, object, gender, number, or tense (having some experience with the German language, fellow learners can understand the frustration of a single verb mapping to 10+ different conjugation forms). Therefore, it is very easy from a syntactic perspective to replace a complex word with a simple one: the only difficulty is identifying which words are complex, and what synonyms or similar words can serve as substitutions.
Step 1: Recognizing complex Chinese words and Named Entities
For any NLP task, the first step of the process is tokenization. I will use the Chinese NLP package jieba for easy tokenization of our text:
import jieba
# tokenize sentence:
tokens = jieba.lcut(sentence)
tokens = [token for token in tokens if not re.match(r'^\W+$', token)] # remove punctuation
Now that the sentence is split into tokens, let's perform named entity recognition (NER). This identifies named entities like names, places, organizations, etc which should not be simplified (e.g. you can't reduce the complexity of "Barack Obama" or "Amsterdam"). In Python, I use the modelscope package with a pre-trained pipeline from DAMO Academy Alibaba:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
ner_pipeline = pipeline(Tasks.named_entity_recognition,
'damo/nlp_raner_named-entity-recognition_chinese-base-news')
ner_output = ner_pipeline(sentence)['output'] # run NER pipeline, generate tokens
tokens_ner = list(set([d['span'] for d in ner_output if len(d['span'])>1])) # get NER>1 character
tokens_no_ner = list(set(tokens) - set(tokens_ner)) # get all tokens that are NOT named entities
Step 2: Identifying complex words
Now we have a list of tokens, both simple and complex. How do we define simple vs complex? I will take two approaches: first through the token's HSK rating, and second through its frequency rating. HSK (Hanyu Shuiping Kaoshi) is a measure of Chinese proficiency for foreign speakers, and it includes a vocabulary list with a total of about 11,000 words ranked from 1 to 9 (1 being beginner level, 9 being most advanced). While not a perfect capture of difficulty, low-rank HSK words are generally learned first and are typically easier to read. So, any word within the HSK vocabulary that is above level 5 could be considered "complex", or at least more likely to have a synonym or similar word within HSK 1-5. My other measure of complexity is with frequency; words and characters that appear rarely in written content are less likely to be known by a reader, and might be replaced with more frequently occurring words.
Building vocabulary datasets
To implement my complex word identification scheme, I build two custom dictionaries for the HSK data and the frequency data, respectively. I retreived .csv formatted HSK data from github and vocab with frequency data from the Beijing Language and Culture University, with UTF-8 encoded versions collected here. From the BLCU data, I used the literature frequency list because the global list collected from all corpus sources had some unusual results that might skew general content analysis, like "第" being the top most frequent character.
With the data in hand, I formatted them as follows:
### import packages
import pandas as pd
import numpy as np
### formatting HSK level data
HSK = pd.read_csv("hsk30.csv")
HSK.index = HSK['Simplified']
HSK.rename(columns={'Level':'level'}, inplace=True)
HSK.drop(labels=['Simplified', 'Traditional', 'Pinyin', 'WebNo', 'ID', 'POS', 'WebPinyin', 'OCR', 'Variants', 'CEDICT'], axis=1, inplace=True)
HSK.replace(to_replace='7-9', value='7', inplace=True)
HSK['level'] = HSK['level'].astype(int)
HSK_dict = HSK.to_dict()['level']
### formatting frequency data
blcu = pd.read_csv('literature_wordfreq.release_UTF-8.txt', header = None, sep="\t",)
blcu.rename(columns={0:"character", 1:"frequency"}, inplace=True)
blcu.set_index("character", inplace=True)
blcu["frequency"] = blcu["frequency"].rank(pct=True)
The resulting data structures look like this:
HSK_dict: {'爱': 1, '爱好': 1, '八': 1, '爸爸|爸': 1, '吧': 1, '白': 3, ... }
blcu.head():
frequency
character
的 1.000000
了 0.999997
是 0.999994
我 0.999992
在 0.999989
HSK_dict has character keys and HSK level values, while the BLCU data is a Pandas DataFrame with character index and a ranked frequency column.
Using the datasets for complex word identification
Let's implement complex word identification using my new data structures:
def find_complex_words(tokens: list, HSK_thresh:int, freq_thresh:float):
complex_HSK = [token for token in tokens if (token in HSK_dict and HSK_dict[token]>HSK_thresh)] # find all tokens above HSK level
complex_freq = [token for token in tokens if (token in blcu.index and blcu.loc[token].values[0]<freq_thresh)] # find all tokens below freq level
complex_words = list(set(complex_HSK).union(complex_freq)) # combine by union
return complex_words
complex_words = find_complex_words(tokens_no_ner, HSK_thresh=5, freq_thresh=0.98)
Steps 3 and 4: Finding and ranking substitution candidates
To find potential substitution candidates, let's apply a standard NLP technique of creating word embeddings for each word in our BLCU vocabulary, and calculating the cosine similarity between each word and every other word. The words with the highest corresponding cosine similarity will likely be the best candidates! For this task, I only look at the top 50000 most-frequent characters, as the memory requirement to cross-compute larger than a 50000x50000 size matrix became too unreasonable.
### import statements
import torch
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('BAAI/bge-large-zh-v1.5') # this will be our word embedding model
### calculate similarity of embeddings
vocab = list(blcu.iloc[:50000].index) # only take top 50,000 most frequent words
embeddings = model.encode(vocab) # create embeddings of each word
similarity_t = model.similarity(vocab, vocab) # calculate similarity -> requires lots of memory!
### sort by similarity value, get top 15 results
top_similar = torch.flip(np.argsort(similarity_t, axis=1)[:,-16:-1], dims=(1,)).numpy().tolist()
One last step. It's important that the part of speech (POS) tag of a candidate substitution matches the original complex word. We don't want to replace a noun with a verb! I use the Chinese package 'thulac' to get the POS tags of the top similar words and filter out nonmatching tags. I also add a frequency-based filter for the list of similar words -- I also don't want to replace a complex word with an even more complex one, even if it is a great synonym!
import thulac
thu1 = thulac.thulac()
similarity_dict = {}
for idx in range(len(top_similar)):
freq_difference = 0.99 # hyperparameter for the max freq difference between original, similar words
base_word = blcu.iloc[idx,0] # get the original word
base_freq = blcu.iloc[idx,0].values[0] # get the original word frequency rank
top_list = list(blcu.iloc[top_similar[idx],0]) # get the similar words
base_flag = thu1.cut(base_word)[0][1] # original word flag
idx_list = []
for word in top_list:
sim_flag = thu1.cut(word)[0][1] # POS tagging with thulac
sim_freq = blcu.loc[word].values[0] # get similar word freq
if sim_flag==flag and sim_freq < word_freq*freq_difference:
idx_list.append(word) # only add matching POS words with high freq to dict
similarity_dict[base_word] = idx_list
The result is a dict with Chinese word keys, with the value being a list of the top most-similar words.
Step 5: Replacing words iteratively
Although our potential candidate substitutions have been identified and are already ranked by their cosine similarity to the complex word, let's also verify that they are a good fit within the original sentence context! To do so, we can replace the word with the candidate in the sentence and compute the cosine similarity between the new and original sentence. The candidate sentence with the highest cosine similarity is probably going to be the best fit, and we can replace the original sentence with this candidate.
I make this an iterative process, so that if there are multiple complex words in a sentence, replacement occurs word-by-word:
def choose_and_replace(sentence: str, word: str, candidates: list):
embed_orig = model.encode(sentence) # get original embedding
similarity = []
for candidate in candidates:
new_sentence = sentence.replace(word, candidate) # new sentence with word replaced
embed_new = model.encode(new_sentence) # create embeddings
similarity.append(np.float32(model.similarity(embed_orig, embed_new)[0][0])) # calculate similarity
best_idx = int(np.argmax(similarity))
sentence = sentence.replace(word, candidates[best_idx])
return sentence
simple_sentence = sentence # start with the original sentence
for word in complex_words: # iterative process
candidates = similarity_dict[word]
simple_sentence = choose_and_replace(simple_sentence, word, candidates) # build our new replaced sentence
Conclusion
The output 'simple_sentence' is our new, lexically-simplified result! Let's look at an example sentence and see how our pipeline simplifies the output:
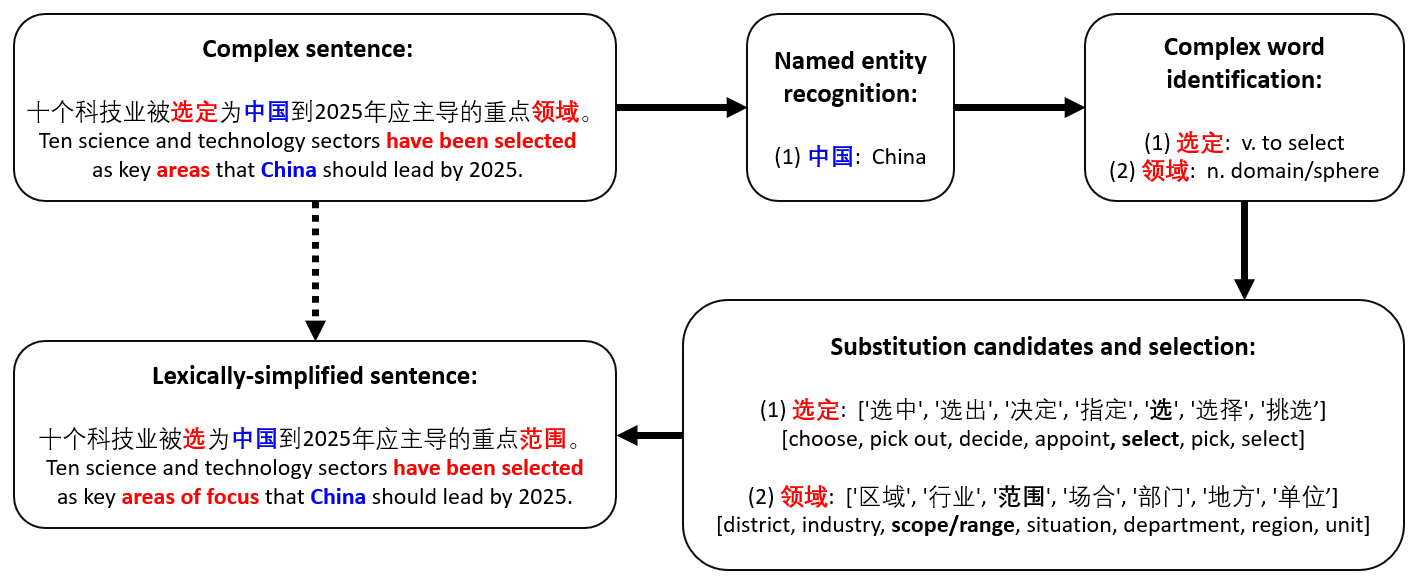
That concludes Part 2 of this project -- a LS pipeline using NLP tools! Of course, we will need to evaluate the performace of this pipeline - see the future Part 4 page for details. But for now, let's look at an alternative approach to simplification: using a fine-tuned BART model.
Continued in Part 3...
References
[1] Al-Thanyyan et al., "Automated Text Simplification: A Survey," ACM Computing Surveys, 52, 2, https://doi.org/10.1145/3442695 (2024)