
Chinese Text Simplification for Reading Comprehension (Part 3)
Part 3 Summary
I describe my process of fine-tuning and applying a Chinese language BART model to achieve generalized text simplification.
Fine-tuning a BART model for sentence-level text simplification
Bidirectional and Auto-Regressive Transformer (BART) is a sequence-to-sequence model proposed by Lewis et al. [1] which uses an encoder and decoder for NLP tasks. For some in-depth explanations, check out these resources for sequence-to-sequence models, BERT, and BART. I will be fine-tuning an existing BART model for a sequence generation task: generating a simplified Chinese sentence based on a complex sentence input!
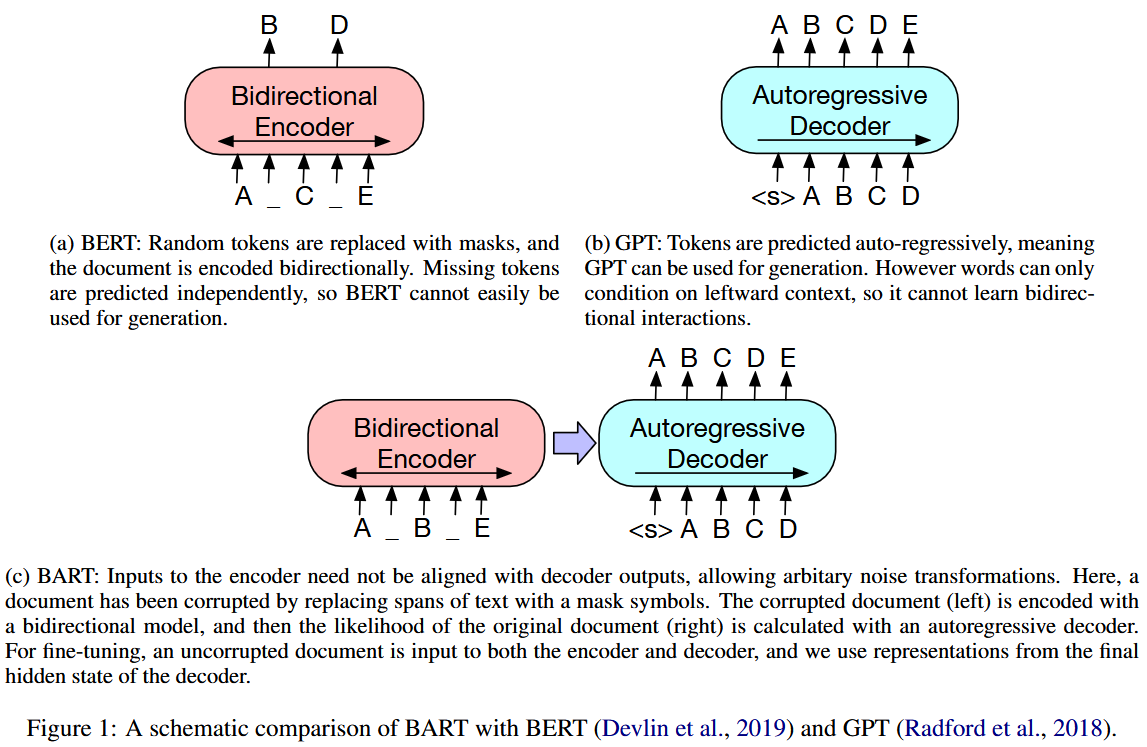
Fine-tuning BART for text simplification tasks has been demonstrated in English [2] as well as Chinese [3] and has shown performance better than large language models like GPT 3.5 when properly fine-tuned. I will be using a BART model trained on Chinese language data, CPT/Chinese BART, available on HuggingFace: https://huggingface.co/fnlp/bart-base-chinese. The model was implemented from the architecture described in Shao et al. [4]
Chinese BART is trained from masking sequences to predict the masked word; it is not trained for text simplification and will need to be fine-tuned. Let's get into how to do that!
Data for fine-tuning
The concept of fine-tuning is simple enough -- you use the pre-trained model with its preexisting model weights and biases, and continue training the model from its current state using task-specific data. In this case, I want to train Chinese BART with text simplification parallel data - a complex sentence input, with a simple sentence to be predicted as the output.
As I discussed in part 1 of this project, the MCTS paper [3] provides a dataset of 691,474 pseudo-simplified sentence pairs, generated by machine-translating complex Chinese sentences from the People's Daily Corpus to English, applying English TS tools, and retranslating the simplified sentences back to Chinese.
Since this dataset is "pseudo" data coming from machine translation, the fluency of the output is unfortunately not guaranteed. However, at the time of writing there is a significant lack of datasets for Chinese language TS compared to other languages like English, so the MCTS dataset is one of the best options available.
Preprocessing and tokenizing data
Since our BART model is prepared on HuggingFace, we can use the HuggingFace transformers package and framework for our fine-tuning. Let's start by preparing our data. An important feature to note in Chinese BART is that Chinese text does not contain spaces separating words, but the BART tokenizer is expecting this -- so let's add spaces between words in each sentence with jieba:
import numpy as np
import jieba
import pickle
from transformers import TrainingArguments, Trainer
from datasets import load_dataset
from datasets import Dataset
from transformers import BertTokenizer, BartForConditionalGeneration
tokenizer = BertTokenizer.from_pretrained("fnlp/bart-base-chinese")
model = BartForConditionalGeneration.from_pretrained("fnlp/bart-base-chinese")
def pre_tokenize(sentence):
return " ".join(jieba.lcut(sentence)) # add spaces to sentence for tokenizer
def preprocess_data(filename: str, start: int, stop: int):
with open(filename, encoding="utf8") as f:
lines_orig = f.read().splitlines()
return [pre_tokenize(line) for line in lines_orig]
Aside: in a previous version of this pipeline, I also attempted to add HSK tokens for HSK levels 4, 5, 6, 7-9 to each corresponding word in the text. The idea behind this is to train BART to substitute or remove higher-level HSK words with simpler words. However, the MCTS pseudo dataset does not contain enough lexical simplification between the input and target sentences for this method to be effective.
Now we can load the pseudo data from the MCTS paper, run it through our preprocessing function, and convert it into a HuggingFace Dataset object. Here, I am using 500,000 sentence pairs, with an 80/20 split for training and evaluation. As the dataset is already shuffled, we can load the train and eval set directly:
start = 0
stop = 500000
split = 450000
lines_complex = preprocess_data('zh_selected.ori', start, stop)
lines_simple = preprocess_data('zh_selected.sim', start, stop)
data_dict = {'complex': lines_complex[start:split], 'simple': lines_simple[start:split]}
ds_train = Dataset.from_dict(data_dict)
data_dict = {'complex': lines_complex[split:stop], 'simple': lines_simple[split:stop]}
ds_eval = Dataset.from_dict(data_dict)
Here's a look at the first training example in the Dataset. You can see that the HSK tokens were added to a few words, which are at HSK level 4:
ds_train['complex'][0]: '75 公斤 级 比赛 3 个 项目 的 第一名 均 为 中国 选手 李顺柱 获得 。'
(The first place in all three events of the 75 kg competition was won by China's Li Shunzhu.)
ds_train['simple'][0]: '中国 选手 李顺珠 在 75 公斤 级 三 个 项目 中 获得 第一名。'
(China's Li Shunzhu won first place in three events in the 75 kg category.)
Now, tokenize the preprocessed data. Here I use a max_length of 128, with truncation for larger inputs and padding for smaller inputs:
# tokenize data
max_length = 128
def batch_tokenize_data(data):
inputs = [example for example in data['complex']]
targets = [example for example in data['simple']]
model_inputs = tokenizer(inputs, max_length=max_length, padding='max_length', truncation=True)
labels = tokenizer(targets, max_length=max_length, padding='max_length', truncation=True)
model_inputs['labels'] = labels['input_ids']
return model_inputs
tokenized_data_train = ds_train.map(batch_tokenize_data, batched=True)
tokenized_data_eval = ds_eval.map(batch_tokenize_data, batched=True)
Hyperparameter search using Optuna
To fine-tune this BART model, I have to make some decisions about the training parameters like batch size, learning rate, etc. The best way to determine optimal hyperparameters is to use optimized tuners like Optuna, which can automatically search over your defined hyperparameter space. Let's perform tuning using the search space defined below:
# optuna fine-tuning
import optuna
import torch
def search_space(trial):
# Define hyperparameter search space
return {
"learning_rate": trial.suggest_float("learning_rate", 1e-5, 5e-4, log=True),
"per_device_train_batch_size": trial.suggest_categorical("per_device_train_batch_size", [4, 8, 16]),
"num_train_epochs": trial.suggest_int("num_train_epochs", 3, 10),
"weight_decay": trial.suggest_float("weight_decay", 1e-5, 1e-2, log=True)
}
# Define training arguments
def model_init():
# Function to initialize the model for Trainer
from transformers import BartForConditionalGeneration
return BartForConditionalGeneration.from_pretrained("fnlp/bart-base-chinese", local_files_only=True)
def compute_metrics(eval_preds):
prediction_tokens = eval_preds.predictions
prediction_text = [tokenizer.decode(tokens, skip_special_tokens=True) for tokens in prediction_tokens]
sari_score = sari.compute(
predictions=prediction_text, # model output
references=[[simple] for simple in tokenized_data_eval.select(range(5000))['simple']], # reference simple sentences
sources=tokenized_data_eval.select(range(5000))['complex'] # complex sentence
)
return {"sari": sari_score["sari"]}
def preprocess_logits_for_metrics(logits, labels):
# This is a memory leak workaround to avoid storing too many tensors that are not needed
pred_ids = torch.argmax(logits[0], dim=-1)
return pred_ids
training_args = TrainingArguments(
output_dir = "./bart_hypersearch",
eval_strategy = "epoch",
per_device_eval_batch_size = 1,
eval_accumulation_steps = 1,
logging_dir = "./logs",
greater_is_better = True,
)
trainer = Trainer(
model_init=model_init,
args=training_args,
train_dataset=tokenized_data_train.select(range(15000)), # Use a subset for quick tuning
eval_dataset=tokenized_data_eval.select(range(5000)),
processing_class = tokenizer,
compute_metrics = compute_metrics,
preprocess_logits_for_metrics=preprocess_logits_for_metrics, # preprocesses before sending to compute_metrics()
)
# Run Optuna hyperparameter search
best_trial = trainer.hyperparameter_search(
direction="maximize", # For maximizing performance (adjust as needed)
hp_space=search_space,
n_trials=10 # Number of trials
)
print(best_trial)
The hyperparameter search took an hour or two on an A100 GPU in Google Colab. Here were the results of the best trial:
BestRun(run_id='4',
objective=33.830690227020675,
hyperparameters={'learning_rate': 0.00010879820645860841,
'per_device_train_batch_size': 128,
'num_train_epochs': 9,
'weight_decay': 0.001750272177978174},
run_summary=None)
Fine-tuning BART with final parameters
Now, set up the trainer using the final params and begin model fine-tuning with trainer.train():
best_params = best_trial.hyperparameters
training_args = TrainingArguments(
output_dir = "./bart_simplification",
eval_strategy = "epoch",
save_strategy = "epoch",
learning_rate = best_params["learning_rate"],
per_device_train_batch_size = best_params["per_device_train_batch_size"],
num_train_epochs = best_params["num_train_epochs"],
weight_decay = best_params["weight_decay"],
eval_accumulation_steps = 1,
per_device_eval_batch_size = 1,
logging_dir = "./logs",
logging_steps = 500,
greater_is_better = True, # maximize SARI
)
trainer = Trainer(
model = model,
args = training_args,
train_dataset = tokenized_data_train,
eval_dataset = tokenized_data_eval,
processing_class = tokenizer,
compute_metrics = compute_metrics,
preprocess_logits_for_metrics = preprocess_logits_for_metrics,
)
trainer.train()
I used the same A100 GPU to perform the training step. Let's look at the loss during training:
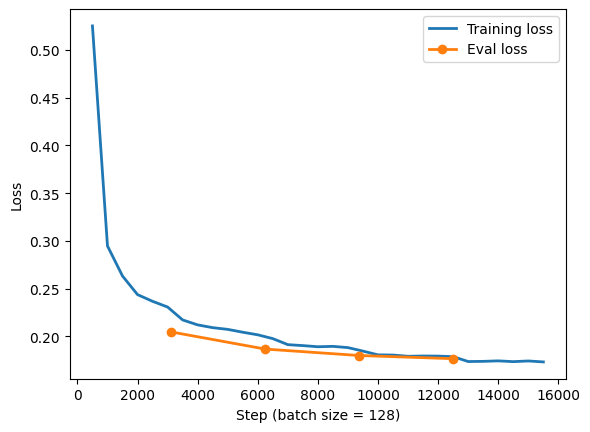
I did not train the full 9 epochs for two reasons: validation loss leveling out (avoid overfitting), and high remaining runtime on the A100 GPU. The total training time was 5.5 hours. Regardless, with the final fine-tuned model, we can make a sample prediction on our dataset:
from transformers import Text2TextGenerationPipeline
text2text_generator = Text2TextGenerationPipeline(model, tokenizer)
output = text2text_generator(sentence, max_length=128, do_sample=False)[0]['generated_text'].replace(" ","") # remove spaces for detokenization
Example ('complex'): '75公斤级比赛3个项目的第一名均为中国选手李顺柱获得。'
(The first place in all three events of the 75 kg competition was won by China's Li Shunzhu.)
Example ('simple'): '中国选手李顺珠在75公斤级三个项目中获得第一名。'
(China's Li Shunzhu won first place in three events in the 75 kg category.)
Fine-tuned BART output: '75公斤级三个项目的第一名均由中国选手李顺柱获得。'
(The first place in all three events in the 75kg category went to China's Li Shunzhu.)
Not bad! It looks like the output of the fine-tuned model is at least fluent and can produce reasonable output. But it can be pretty difficult to tell if the output is sufficiently simple, or if it requires further simplification.
Conclusion
In Part 3, I've described a way to preprocess and tokenize complex/simple sentence pairs from a large dataset and apply them for fine-tuning on the Chinese BART model. The output looks fluent and captures the meaning of the original complex sentence, but how can we tell if the model is actually simplifying the sentence rather than simply rewording it? Let's tackle that in Part 4, where I evaluate the performance of this BART model as well as our LS pipeline described in Part 2.
Continued in Part 4!
References
[1] Lewis et al., "BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension," https://doi.org/10.48550/arXiv.1910.13461 (2019)
[2] Sun et al., "Teaching the Pre-trained Model to Generate Simple Texts for Text Simplification," https://doi.org/10.48550/arXiv.2305.12463 (2023)
[3] Chong et al., "MCTS: A Multi-Reference Chinese Text Simplification Dataset," https://doi.org/10.48550/arXiv.2306.02796 (2024)
[4] Shao et al., "CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation," https://doi.org/10.48550/arXiv.2109.05729 (2021)