
Chinese Text Simplification for Reading Comprehension (Part 1)
A personal project in NLP, ML, and BART modeling
Part 1 Summary
I introduce my project to implement Text Simplification using NLP and ML for Chinese language learning. I discuss the benefits of Text Simplification, Lexical Simplification, and outline my approach to this problem. Part 1 is an overview of the project; future articles cover the technical aspects and results.
The problem
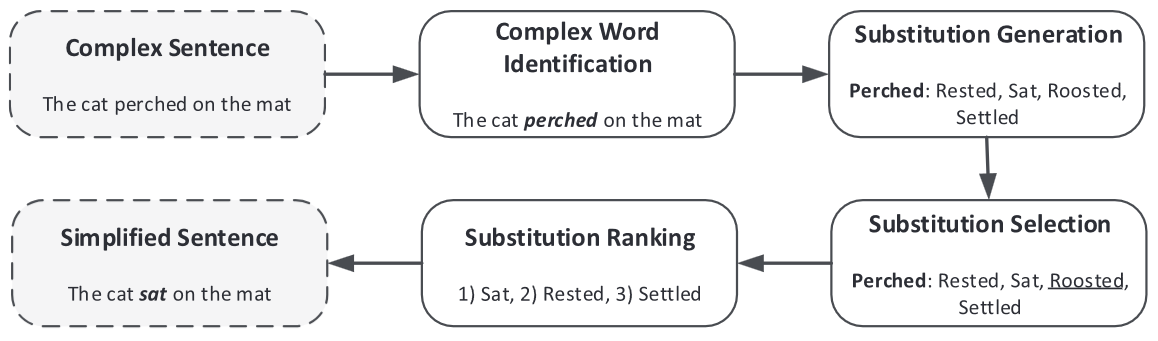
Text simplification (TS) is the process of reducing the linguistic complexity of written text in order to improve readability for people with low reading skills, children, non-native speakers, or language learners. A subset of this, called lexical simplification (LS), is focused only on reducing the word complexity while the sentence structure remains unchanged. As a language learner of Chinese, I became interested in the idea of Chinese TS and LS to serve as a tool to improve my reading abilities.
How can text simplification improve reading skills? Through extensive reading -- reading passages in which a large amount (about 95%) of the words are understood. With this method, readers can focus more on the language's natural cadence and read at faster speeds, compared with more intensive reading where a large amount of words are unknown and more time is spent looking up new words. Because most of the words are understood in extensive reading, it's easier to use context-clues to infer the meaning of new vocabulary.
My goal is to implement a Chinese language TS/LS pipeline to automatically simplify online content to promote intensive reading practice.
My approach
My overall approach is to employ both NLP tools and ML language models like BART to implement Chinese TS/LS. I will implement my project in Python, which has a vast array of ML and NLP packages and models. In future articles, I will describe my implementation of an LS pipeline using NLP tools, a BART pipeline via fine-tuning, combined approaches utilizing both traditional NLP + BART, evaluation tools, results, and final implementation for online content simplification.
Datasets
In this project I will be leveraging Chinese TS parallel texts from the Multi-Reference Chinese Text Simplification Dataset (MCTS) [2]. MCTS contains 723 complex sentences, each accompanied by five sentence simplifications authored by native Chinese speakers. Chong et al. also provide a dataset of 691,474 pseudo-simplified sentence pairs, generated by machine-translating complex Chinese sentences from the People's Daily Corpus to English, applying English TS tools, and retranslating to Chinese.

As the MCTS dataset is too small to apply to machine learning models, I will use the pseudo dataset for training and evaluation (see Part 3 of this project). The MCTS dataset can then serve as a test set for evaluating the final model.
I also employ vocabulary data for the traditional NLP methods; I will cover this in Part 2.
Project outline
- Part 2: Lexical simplification using NLP tools.
- Part 3: Text simplification by fine-tuning Chinese BART.
- Part 4: Evaluation metrics, performance of NLP-LS and BART-TS.
- Part 5: Final implementation to simplify online content.
Let's begin in part 2 with traditional NLP approaches for LS!
References
[1] Al-Thanyyan et al., "Automated Text Simplification: A Survey," ACM Computing Surveys, 52, 2, https://doi.org/10.1145/3442695 (2024)
[2] Chong et al., "MCTS: A Multi-Reference Chinese Text Simplification Dataset," https://arxiv.org/abs/2306.02796 (2024)