
Building a resume-job matching service
(Part 2)
A personal project in web scraping, ML/NLP, and cloud deployment
Part 2 Summary
I describe my implementation of a web scraper to retreive job details from a given user query on linkedin.com, including best practices for navigating security and anti-scraping measures.
Reminder, full project code can be found on my github repository.
Basics of web scraping
As I discussed in the overview of this project (see Part 1), my first goal is to implement a
web scraper that can retreive job listings from the LinkedIn job board for any given user query.
Let's begin with the scraping basics, and later delve into how to navigate anti-scraping policies.
At its core, my web scraper will use the requests package to
send and receive requests from web pages, and BeautifulSoup to
process the retrieved html:
import requests
from bs4 import BeautifulSoup
response = requests.get(url, cookies=cookies, headers=headers, proxies=proxies, timeout=10)
soup = BeautifulSoup(response.text, "html.parser")
# do something here with soup to extract the data you want
Obtaining the correct URL, headers, cookies, and setting appropriate proxies will be the key to successful web scraping. Let's look at them in order.
Setting the URL
My web scraper uses 3 URLs: (1) the base page job search URL for LinkedIn, (2) the API URL which retrieves more results after the base page, and (3) the individual URLs of each job listing. The base page URL is accessed with:
job_title = "Data scientist"
location = "Chicago"
post_time = 2.5
base_url = ("https://www.linkedin.com/jobs/search?keywords"
f"={job_title}"
f"&location={location}"
f"&f_TPR=r{int(post_time*86400)}"
"&position=1&pageNum=0")
Here, post_time is a float that describes how far in days to look back,
but as you can see from the URL, LinkedIn actually provides second-level granularity
(i.e. &f_TPR=r86400 returns jobs posted in the past 24 hours, &f_TPR=r10 returns jobs posted in the
last 10 seconds). The base URL only shows the first page of job results, roughly 10-20; to return
more results, we need to call the LinkedIn API URL which would be activated in the user scrolled down the page
to load more results. By examining the network traffic on the base URL during scrolling, I found the API URL
to be the following:
API_url = ("https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords="
f"{job_title}"
f"&location={location}"
f"&f_TPR=r{int(post_time*86400)}"
f"&start={start}")
With the job_title, location, and post_time the same as before, but with the start
parameter an int describing the starting position of the retrieval (e.g. start=10 returns the job listing
starting from the 10th job of the search results). So by iterating through a changing start
value, we can continually retrieve more and more job postings.
The third URL to retrieve is the URL of the job listing itself, which will be necessary to access in order to obtain the full job description. From the original LinkedIn search page, we can only retrieve the job cards with information like job title, company, and location. I'll go more in detail later about how to find the listing URL.
Getting cookies
Cookies are needed in order to access the API URL from the base page. I made a simple script to get cookies from the initial visit to the job search page:
def get_fresh_cookies(base_url: str, user_agent: str):
session = requests.Session() # Create session to store cookies
headers = {"User-Agent": user_agent}
# Make request to url
response = session.get(base_url, headers=headers)
if response.status_code != 200:
return None # problem making the request
# Extract cookies
cookies = session.cookies.get_dict()
return cookies
from fake_useragent import UserAgent
user_agent = UserAgent().random
cookies = get_fresh_cookies(base_url, user_agent)
Here, I use the UserAgent package to create a randomized user, mimicking a real browser, which helps fool LinkedIn into thinking that the scraper is a real user. Here are some example outputs from the UserAgent():
'Mozilla/5.0 (iPhone; CPU iPhone OS 18_3_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.3 Mobile/15E148 Safari/604.1'
'Mozilla/5.0 (Linux; Android 10; K) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Mobile Safari/537.36'
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36'
Setting the headers
Now to access the LinkedIn job API, we can set the headers. One of the headers is the session ID, which we obtained from getting the cookies.
headers = {
"User-Agent": user_agent, # our random UserAgent
"Csrf-Token": cookies["JSESSIONID"],
"Referer": base_url, # base search URL
}
Setting proxies to avoid detection
Setting proxies is an important part of detection avoidance; they obscure your real IP and make the API believe it is being accessed from a different IP. For small amounts of web scraping this is problably not needed, but making lots of requests in a short amount of time from the same IP could result in your IP being blocked. I'm using IPRoyal to obtain rotating residential proxies: these are residential IPs that automatically change with each new access. So far, I've found that with just 1 GB of bandwidth (about $2-3), I've been able to make a few thousand LinkedIn requests, so the cost is very low for this application.
Your proxy provider will give you the proper proxy information; the format looked something like this:
# proxy setup from IPRoyal
proxy = 'geo.iproyal.com:(REDACT)'
proxy_auth = '(REDACT):(REDACT)_country-us'
proxies = {
'http': f'socks5://{proxy_auth}@{proxy}',
'https': f'socks5://{proxy_auth}@{proxy}'
}
Putting it all together
To recap from above, I've found the proper URL formats to make LinkedIn job searches,
retreived cookies, headers, and set proxies, and now we can use request.get()
to retrieve job data. I've also implemented a few features to avoid detection, namely:
- Use a random UserAgent for each session
- Use rotating residential proxies for each new API call (see below)
- Also, add a random time interval between calls to avoid "robotic" user behavior.
Now to retrieve the job information itself. The scraping process really depends on the website you access, but in the case of the LinkedIn jobs page, here's how it looks:
response = requests.get(url, headers=headers, proxies=proxies, cookies=cookies, timeout=10) # make request from API URL
soup = BeautifulSoup(response.text, "html.parser") # extract html
job_cards = soup.find_all("div", class_="base-card") # this gets all the job cards
if not job_cards:
return None # no jobs found
# Get job posting data from each posting:
jobs = []
for job in job_cards:
title_elem = job.find("h3", class_="base-search-card__title")
company_elem = job.find("h4", class_="base-search-card__subtitle")
location_elem = job.find("span", class_="job-search-card__location")
link_elem = job.find("a", class_="base-card__full-link") # link to job posting
title = title_elem.text.strip() if title_elem else "N/A"
company = company_elem.text.strip() if company_elem else "N/A"
job_location = location_elem.text.strip() if location_elem else "N/A"
job_link = link_elem.get("href") if link_elem else "N/A"
job_des, job_time = scrape_job_description(job_link) if link_elem else "N/A"
jobs.append({"title": title,
"company": company,
"link": job_link,
"posted time": job_time,
"description": job_des,
"location": job_location,
})
To summarize the above, we use BeautifulSoup
to find the html elements that contain the data we want, and extract each element with
.text.strip(). However, extracting the job description and posted
time requires a little more effort. Using the link to the job listing, we need to make a
new request and extract the job description and posted time from the new html:
def scrape_job_description_single(url: str):
headers = {"User-Agent": UserAgent().random, # make new random user for each job
"Referer": "https://linkedin.com",
}
try:
# Make request to full job posting page
response = requests.get(url, headers=headers, proxies=proxies, timeout=15)
if response.status_code != 200:
print(f"Failed to retrieve job details: {response.status_code}")
return None, None
else:
soup = BeautifulSoup(response.text, "html.parser")
job_description_elem = soup.find("div", class_="description__text")
job_des = extract_clean_text(job_description_elem)
job_time = extract_job_time(soup)
return job_des, job_time
except Exception as e:
print(e)
return None, None
We make a request to the job posting url, and again use BeautifulSoup to extract the job description element. But the element contains a lot of html formatting (like <p> and <li> tags), so we need a small function to clean it up:
def extract_clean_text(element):
# Extracts clean text with spacing preserved from bs4.element.tag
block_tags = {'p', 'li', 'br'}
texts = []
for child in tag.descendants:
if child.name == 'br':
texts.append('\n')
elif child.name in block_tags:
texts.append('\n' + child.get_text() + '\n')
# Join, normalize newlines/spaces
combined = ''.join(texts)
lines = [line.strip() for line in combined.splitlines()]
result = '\n'.join(line for line in lines if line)
return result
We also need to extract the exact time at which the job was posted. If we only scrape the time element from the job card, we will get a vague text like "2 hours ago". To get the exact time, we can search through the webpage scripts to find the original time stamp:
def extract_job_time(soup):
scripts = soup.find_all("script")
post_time = "N/A"
for script in scripts:
if script.string and 'JobPosting' in script.string:
json_text = re.search(r'({.*"@type":"JobPosting".*})', script.string, re.DOTALL)
job_json = json.loads(json_text.group(1))
post_time = job_json.get("datePosted")
return post_time
This returns the posted time in ISO 8601 format, which looks like this: 2025-04-20T13:38:30Z, which is YYYY-MM-DD with time (T) HH:MM:SS in UTC.
Convert to a DataFrame
From the code above, we can build up a list of job data that can easily
be converted into a Pandas DataFrame using
job_df = pd.DataFrame(job_list):
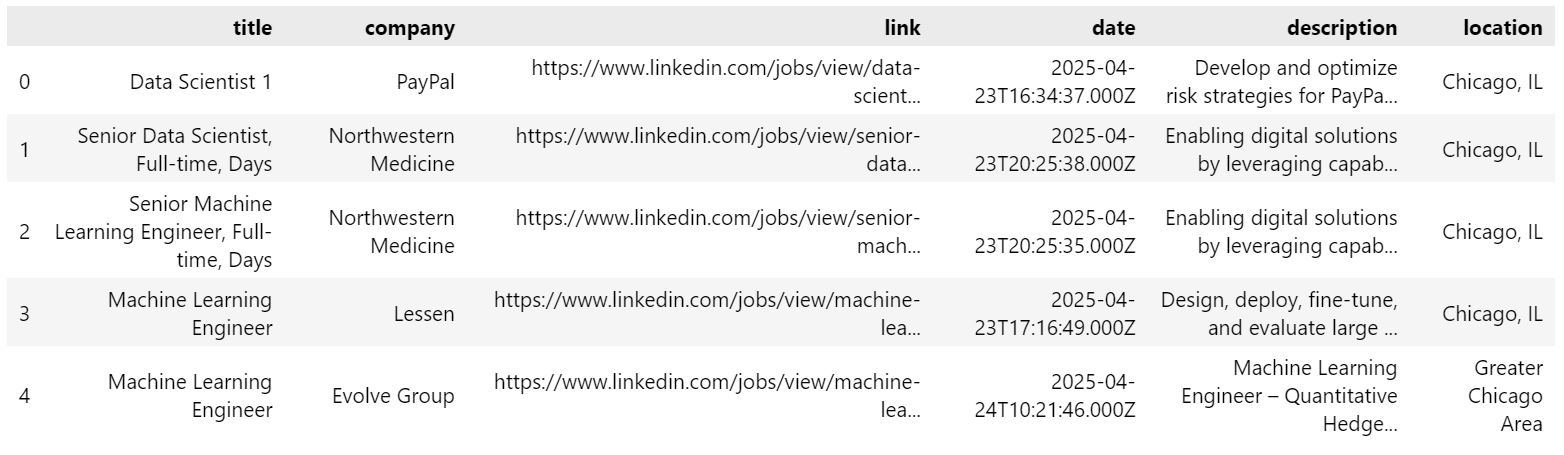
Summary
What have we done so far? Used requests to call the
LinkedIn API after properly formatting the cookies, headers, and proxies for the request;
used BeautifulSoup to find specific html classes to extract
information like job title, company, and location; and finally made a small function to extract
the job description from the full job link.
With this method we can quickly scrape hundreds of job listings from LinkedIn based on the user's query (job title, location, posted date). How can we sort through all this job data to find the most relevant jobs for the user?
Let's look at job-resume matching in Part 3